İyi günler arkadaşlar.
Bugün, başlıktada yazdığı gibi Python 3 ve BeautifulSoup kütüphanesi ile web sitesinden veri almayı anlatacam fakat önce bunu nerede ve nasıl kullanacağınıza örnek vermek istiyorum.
IoT ile uğraşan arkadaşlar illa web sitesi üzerinden veri çekme işlemini kullanırlar. Mesela bahçenize kurduğunuz mini hava istasyonu bilgiyi bir web sitesine yazacak ve siz bilgiyi oradan Python 3 ile alıp ekrana anlık olarak yazdıracaksınız. Şimdi benim elimde hazır olarak hava istasyonu sistemi olmadığı için mynet üzerinden yasal çerçevede kalarak alacağım ve programı Ubuntu ortamında yazacağım. O yüzden Windows kullanıcıları şimdi kodu yazarken vereceğim bazı yerleri parantez içindeki şekilleriyle yazmalılar. Mac kullanıcılarının bir değişiklik yapmaları gerekmemekte.
Öncelikle kütüphanemizi şu kod ile indirelim;
pip3 install beautifulsoup4
Ardından bir dosya oluşturalım ve kütüphanelerimizi yazalım
#!/usr/bin/env python3 #-*-coding:utf-8-*- (Windows için utf-8 yerine cp1254 yazılacak) from bs4 import BeautifulSoup as bs import urllib.request as istek import time
Burada kütüphaneleri çağırırken ‘as bs’ ve ‘as istek’ dememin sebebi ben kod yazarken bana kolaylık sağlaması içindi. Time kütüphanesini kullanırken ise kodu while içine yazacağım için siteye sürekli istek yollamaması için 2 saat bekleteceğim.
while True:
url = "http://www.mynet.com/havadurumu//asya/turkiye/istanbul"
Dediğim gibi önce while döngüsüne aldım ve bilgiyi çekeceğim yerin adresini aldım.
urlOku = istek.urlopen(url)
Az önce kütüphaneleri tanımlarken ‘istek’ diye kısaltmasaydım kodun şekli ‘urllib.request.urlopen(url)’ diye olacaktı ve gereksiz kalabalık olacaktı. Ayrıca burada da urlOku ile web sitesine istek atıyorum ve web sitesine bağlanmış bulunuyorum.
veri = bs(urlOku, 'html.parser')
Yine kısalttığım bir kod ile fazlalıklardan kurtulmuş bulunmaktayım. 🙂 ‘veri’ isimli değişkenin içine ulrOku ile BeautifulSoup’u bağlayıp html verileri toplamış durumdayız. Bu durumda yazdırdığınızda sitenin kaynağını ekrana yazdırır. Yani siz iğneyi bulacağınıza bütün samanlığı ortaya döküyorsunuz.
sicaklik = veri.find_all('span',attrs={'class':'hvDeg1'})
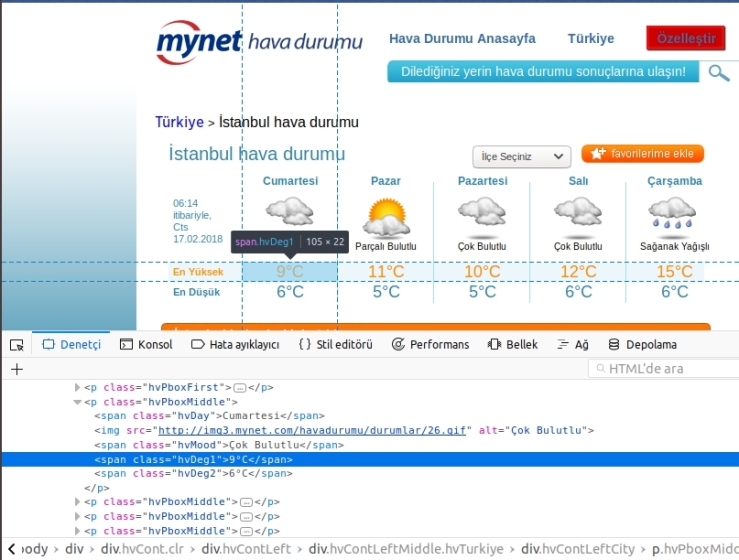
Şimdi samanlardan kurtulma vakti. ‘sicaklik’ değişkeninin içine iğnemizi ‘find_all’ fonksiyonu ile atacağız. Web sitesinden alacağım kısma öğe denetle ile bakarken ‘span’ taginin içinde olduğunu gördüm. Yani siz başka bir işlem yaparken verinin içinde bulunduğu tagi kullanacaksınız. (div, a, body, title, vb.) Peki bir web sitesinde sadece bir tane mi ‘span’ tagi olabir? Elbette hayır. O yüzden ‘attrs’ ile beraber ‘hvDeg1’ classına sahip olacağını söylediğim. Bu işlemi id ile yapmak daha kesin bir çözüm sunuyor bu arada. Eğer kurduğunuz sistemde siteden veriyi id ile çekerseniz daha iyi olur.
print (sicaklik[0].text) time.sleep(2)
‘sicaklik’ içindeki iğnemizi yazıya çeviriyorum ve 2 saniye bekletiyorum. Bu işlemi siz kendi sisteminize göre belirleyebilirsiniz.
Bu yazılık bu kadar, umarım yardımcı olabilmişimdir.
Kodun tam hali: http://link.tl/1mWWe
